Physics Abstraction Layer (PAL)
Architected and led PAL, a C++/Python simulation scene graph used across most Pixar films from Toy Story 3 through Incredibles 2.
Highlights
- Technical lead and architect for PAL core systems.
- Supported production use from Toy Story 3 through Incredibles 2.
- Bridged research code to production reliability.
Tags
C++, Python, FEM, Cloth Sim, Flesh Sim, Hair Sim, Fluid Sim, Node Graph
Contents
- A Moment in Time
- The Structural Trap
- The Reframe
- The Architecture: Building the Bridge
- Production Survival & Hard Lessons
- Outcome
- Broader Reflection
A Moment in Time
When we started PAL, physics-based simulation in film was not a solved problem. We were still figuring out what worked. Research was active. Techniques were evolving. Solvers were being modified between shows - sometimes between sequences. At the same time, production still had to ship films on schedule.
The gap between research and production wasn’t philosophical. It was structural.
The engineering, math, and science was moving quickly, but the infrastructure around it was fragile and expensive to maintain. Most integrations were held together with ingenuity, persistence, and more than a little duct tape. We all knew it.
The real issue wasn’t that anyone was doing poor work. It was that the incentives were misaligned.
The Structural Trap
At the time, simulation infrastructure was effectively funded show-by-show. If a production needed a new solver capability or pipeline upgrade, that production paid for it. When the show wrapped, the integration wrapped with it. Improvements rarely accumulated. The next show inherited fragments, not a platform.
No individual production could justify long-term infrastructure investment. Their responsibility was to deliver the film in front of them, not build durable systems for future films. Even if they wanted to make major upgrades, the cost-benefit math rarely worked under production pressure.
Meanwhile, research kept evolving. Techniques improved. New solvers emerged. But every time the science moved, integration work had to be redone. That made simulation feel risky. Manual methods — even if less powerful — felt safer because they were predictable, known quantities.
We were stuck in a loop: research evolved quickly, integration lagged behind, production paid the tax, and infrastructure remained fragile.
The technology wasn’t mature — and the funding model ensured it stayed that way.
The Reframe
The insight behind PAL was structural.
Instead of treating simulation integration as a show expense, treat it as a studio-level capital investment. If we could build a shared abstraction layer — stable enough for production, flexible enough for research — we could amortize integration costs across films. Research could continue evolving without forcing every show to rebuild its pipeline from scratch.
PAL wasn’t just another simulator. It was a bet that the missing piece wasn’t better physics — it was better infrastructure.
The Architecture: Building the Bridge
If PAL was going to reposition simulation infrastructure as a studio-level investment, it had to satisfy two opposing constraints: stability for production and flexibility for research. That meant we weren’t designing a simulator. We were designing an abstraction boundary.
At a high level, PAL looked like this:
Production UI
(Presto / Houdini / Maya)
│
▼
┌─────────────────┐
│ PAL SCENE │
│ GRAPH │
│ │
│ PalContext │
│ PalObject │
│ Attributes │
│ Relationships │
│ Validation │
│ Serialization │
└─────────────────┘
▲ ▲
│ │
Research Solvers Distributed / Batch
(PhysBAM, etc.) (MPI / Render Farm)
PAL was the stable surface.
Research evolved behind it.
Production tools spoke only to it.
Distributed systems reconstructed it.
Serialization captured it.
Monitoring inspected it.
Everything flowed through the graph.
The Scene Graph
At the center was PalContext, which owned the simulation scene. Every object was created through
it, giving centralized lifetime management, logging, and traversal.
Everything derived from PalObject. Simulators, deformable bodies, meshes, forces, constraints —
all first-class nodes. Objects exposed typed attributes organized into input and output groups.
Objects connected via typed PalRelationship edges.
The graph wasn’t just representation. It was integration.
It made simulation setups:
- Representable as data
- Configurable
- Serializable
- Introspectable
- Toolable
Attributes as the Currency
The most important primitive in PAL was the typed attribute (PalAttr). Attributes carried scalars,
vectors, transforms, meshes, and fields defined over arbitrary discretizations.
Attributes were tagged as PAL_VARYING or PAL_UNVARYING. That small distinction shaped
serialization behavior, UI affordances, validation logic, and frame evolution semantics.
Because attributes were introspectable, UIs could be generated procedurally. Tools didn’t need to know specific solver classes — they could discover attributes at runtime. That decision compounded in value over time.
Relationships as First-Class Citizens
Connections weren’t implicit pointers. They were explicit PalRelationship objects forming semantic
sentences:
- Simulator simulates DeformableBody
- Gravity affects Simulator
- Body has TetrahedralMesh
Attempting to construct a relationship was attempting to make a true statement. Any of the three objects involved (the relationship object included) in the relationship could validate it. If none of the objects did, construction failed. These decisions were typically made by type inspection on the objects, where usually the base class of at least one side of the proposition would be endowed with knowledge of which relationships it supported to which object types. Combined with object factory registries, this made context aware automatic scene construction possible.
This centralized validation at the graph level rather than scattering it across solver code.
The Conversion Registry
We were bridging multiple type systems: solver-native structures, internal math libraries, DCC representations, and file formats.
Instead of writing bespoke adapters everywhere, we built a PalConversionRegistry, which was a
collection of data conversion functions. Conversions registered as PAL_FAST or PAL_SLOW,
their input and output types - which could be an “any” object - and the registry computed the
shortest path between types. Many graph traversals may have been attempted before finding one
that worked. Complex conversions - including file reads, and database extraction - were supported.
The system traded some runtime overhead for enormous integration flexibility — which was the correct trade during a period of rapid evolution.
Procedural Evaluation
Originally, PAL was representational. The data contained in the graph always represented a snapshot in time. Simulator nodes were the scene root. Driver objects advanced time which triggered scene updates.
Later, we added dirty-state tracking and lazy evaluation. If an output was stale relative to inputs,
PalObject::Exec() executed automatically, pulling inputs, performing work, and updating outputs.
The graph became a lightweight dataflow system. Geometry preprocessing became composable. The model
aligned naturally with node-based workflows a growing body of artists already understood in Houdini.
Serialization, Restart, and Inspection
For production viability, simulation setups couldn’t live only in memory.
We built:
- TID (Berkeley DB-backed time-indexed dictionary) serialization
- Binary graph serialization for distributed networking execution
- Restart interfaces for checkpoint/resume
- A CLI runner (
dash) palInfo, which served live API documentation over HTTP- USD serialization
The ability to serialize, restart, override parameters, and inspect state wasn’t ornamental — it was foundational.
Below are examples of palInfo browsing a live PAL schema:
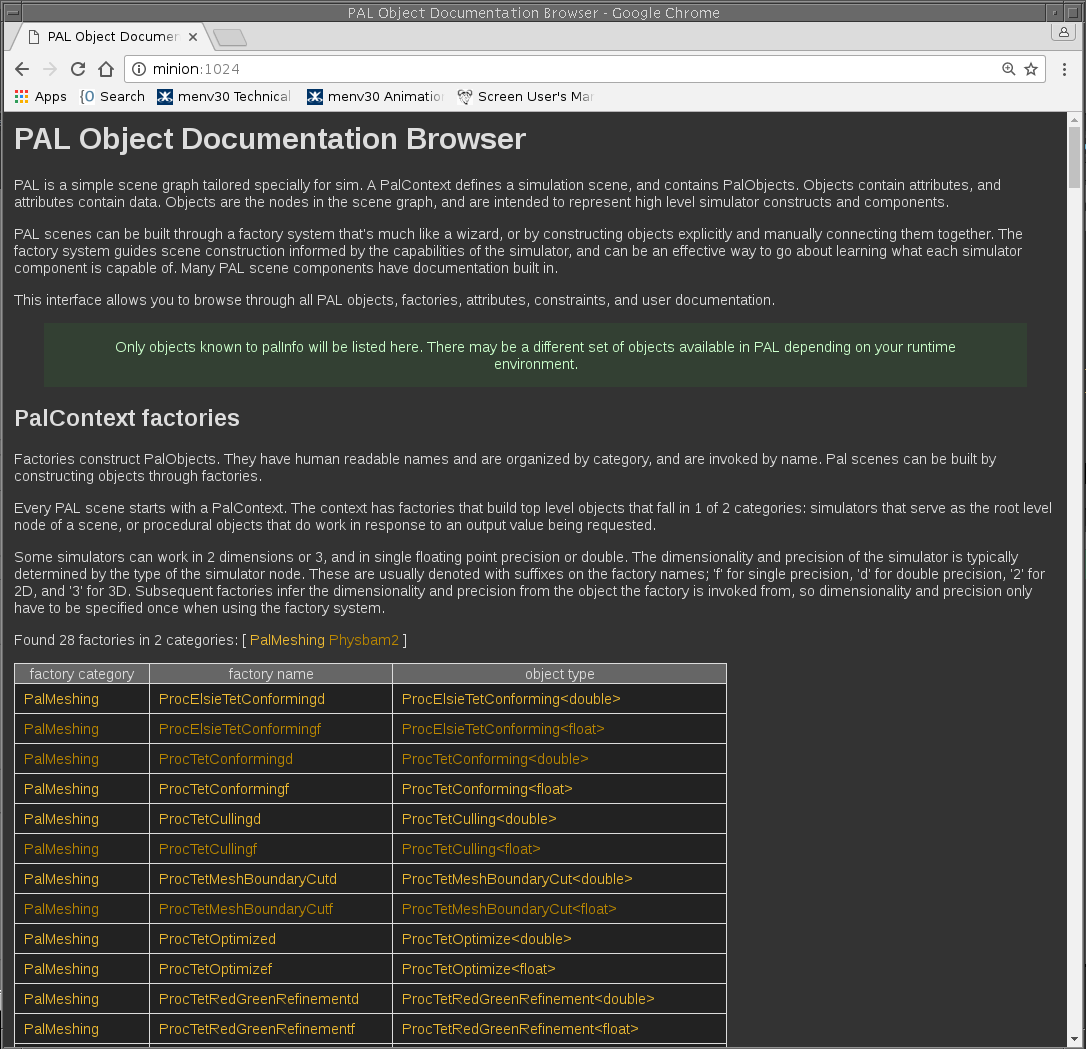
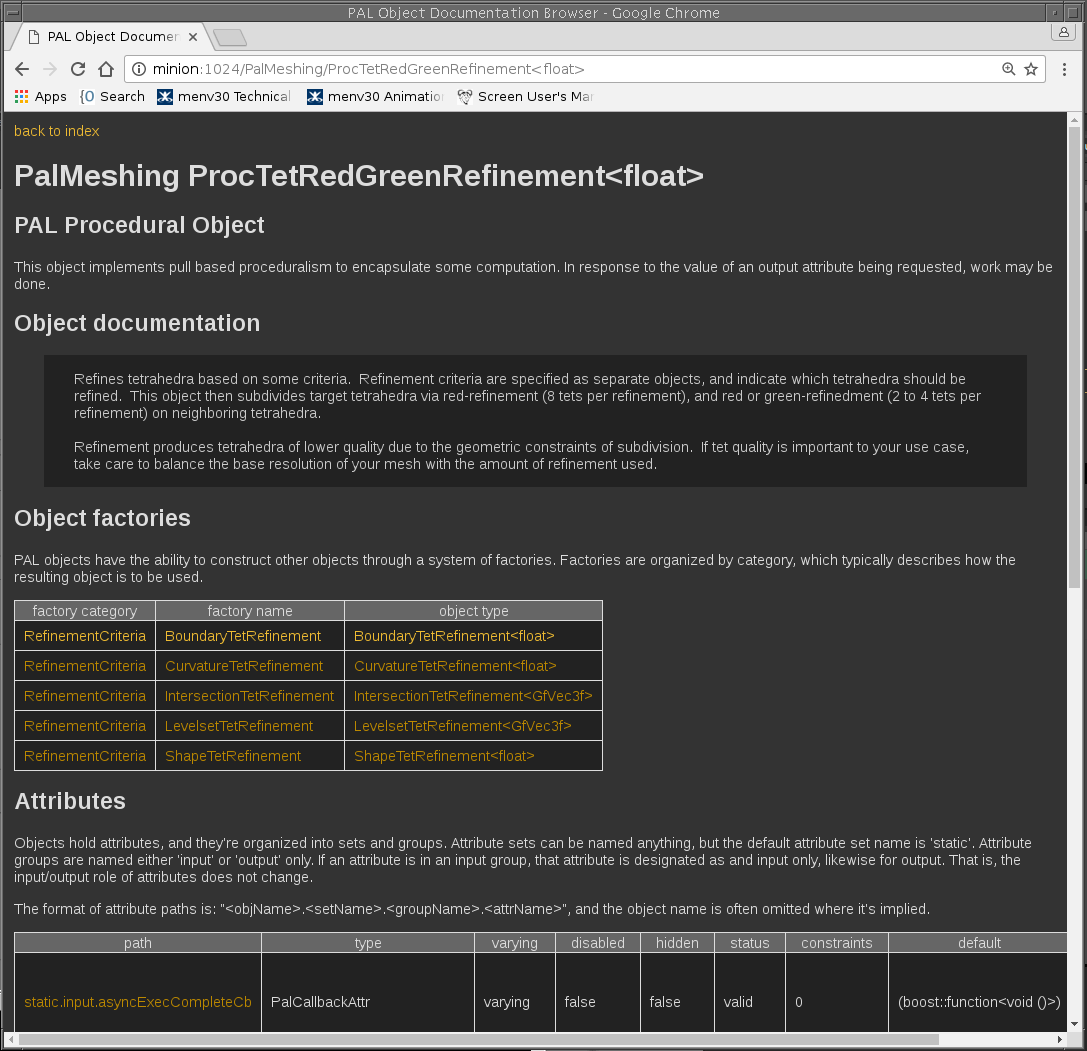
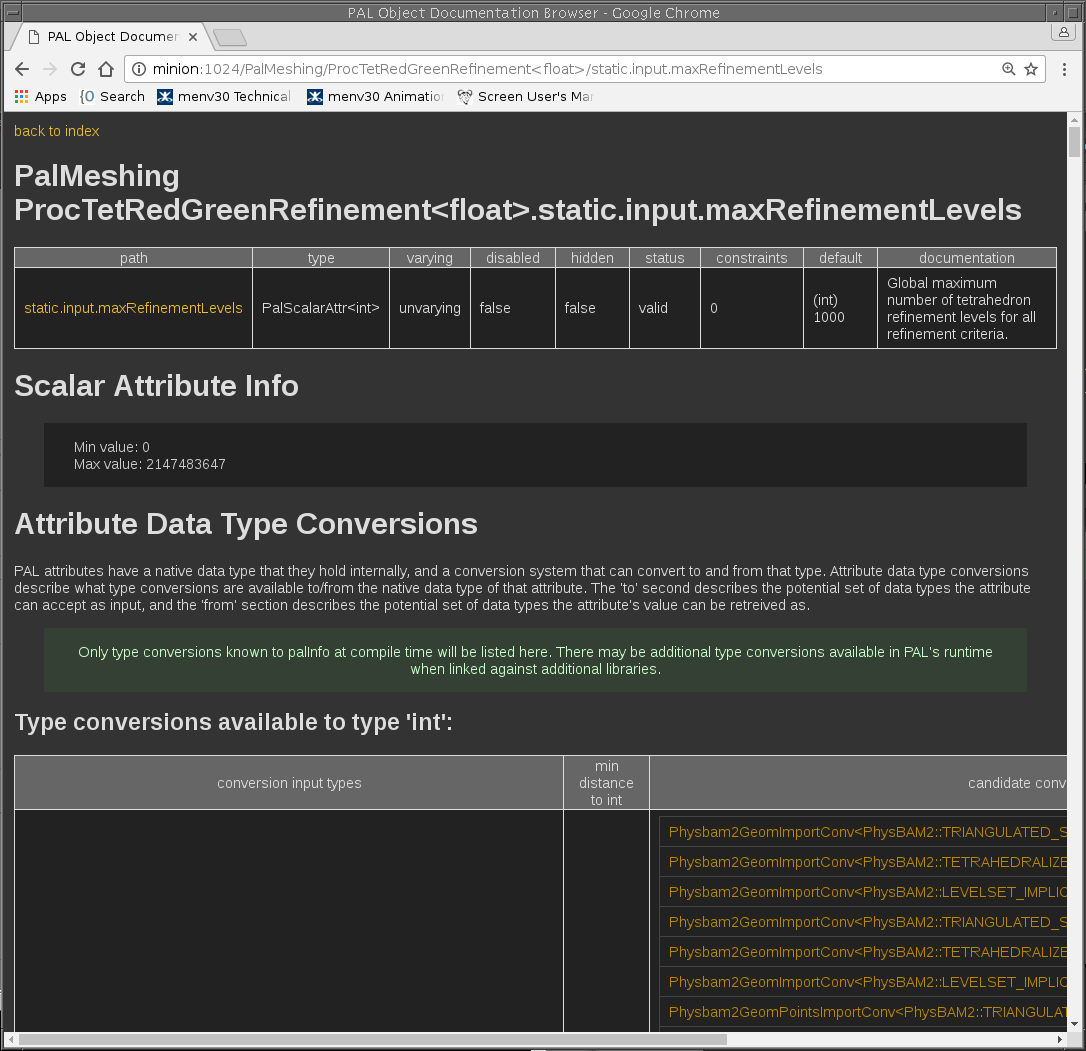
When tools can explain themselves, trust increases. When trust increases, adoption follows.
Background I/O and Distributed Execution
We built PalTaskQueue to offload filesystem and network I/O to background threads. Each filesystem
or network I/O task had its own operator class, arraged in a priority queue by target name. Filesystem
or network write events were queued, while read events caused tasks associated with the requested
resource to be flushed. Outputs used atomic rename-on-complete semantics to prevent partial
concurrent reads. We also avoided costly OS calls by caching filesystem information in memory.
This solved real resource contention problems on the render farm. Throughput and reliability on the farm increased substantially.
For distributed execution, MPI workers reconstructed scene graph instances from binary serializations. Specialized logging and statistic gathering backends centralized distributed output.
Simulations were trackable by an integrated http server that you could point a web browser at, and get live updates with stats drawn in graphs and live logging.
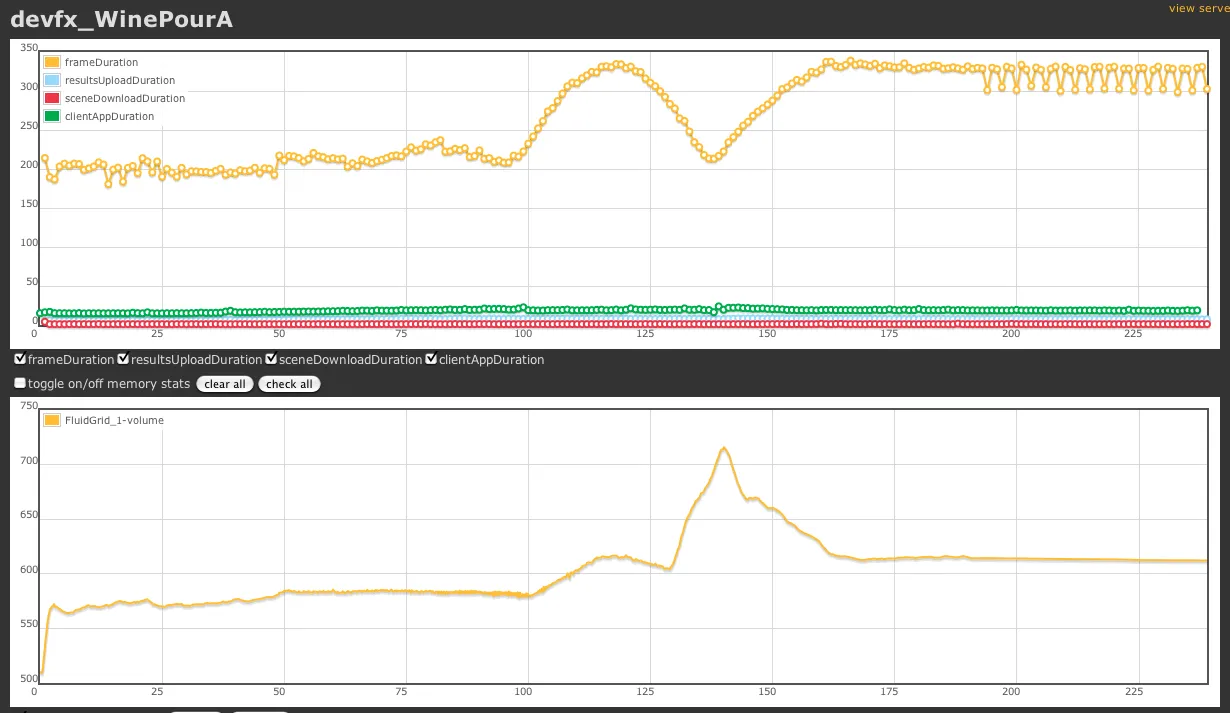
These systems weren’t glamorous. They were what made the architecture survivable.
Production Survival & Hard Lessons
While there was a lot that PAL got right, mistakes were made…
PAL Straddled Eras
Pixar’s legacy software stack outlived its utility and was eventually replaced in a great undertaking, resulting in Presto. Then out of that was born USD. We started PAL way before then, and we didn’t know what the future would look like, but we knew a lot of change was coming.
Many of the systems we built into PAL were focused on the flexibility to transition from legacy
systems to new ones. But once the transitions completed, systems like the PalConversionRegistry
and PalAttr’s data type flexibility became less compelling.
All that machinery was still necessary and used, but it wasn’t ideal as doing a potentially multi-hop graph traversal every time a value changed was more expensive than a purpose built adapter. Had I to do it over again, I might aschew the power and flexiblity of the conversion registry for something more like Rerun.io’s data type adapter API.
Sometimes your dependencies sink you
One of the most consequential design decitions we made was binding PAL to Pixar’s math library, Gf.
At a technical level, Gf introduced real friction. Its linear algebra API was inconsistent in places, and it required specialized build and load-time considerations that made integration into external build systems significantly more complicated than we anticipated. Other internal Pixar libraries had similar integration constraints, but those tended to provide clear structural advantages that justified the cost. Gf, at that time, was harder to defend on those grounds.
The practical consequence was that distributing PAL outside the studio became extremely difficult. We had plans — and approval — to open source it. But untangling PAL from Gf would have required a non-trivial refactor, and the cost wasn’t something any single stakeholder could justify.
In hindsight, a thinner math abstraction layer would have positioned PAL better for portability. Binding to a widely adopted library like Eigen (which had just been released as we were whiteboarding) — or even designing a lightweight internal abstraction over row/column-major storage — would have reduced external friction considerably. We did discuss alternatives, including ILM’s Imath, but alignment pressures and ecosystem realities made that path not possible at the time.
It’s also worth noting that today’s Gf (as shipped with USD) is significantly improved compared to the version we were working with. Given the context and timing, aligning with Gf was understandable. But strategically, it limited PAL’s ceiling more than we realized.
Too many data copies
One of the problems with PAL that would have hampered its use in realtime sim is the fact that PAL wanted to own the data at the API boundaries. In todays systems, you eliminate data copies wherever you can. Before realtime sim was a thing, the cost of the extra data copy was miniscule to the cost of the simulations we ran. It wasn’t a problem at the time, and not doing the data copy introduced the risk of dangling references, which was an unnecessary risk.
PAL deliberately chose correctness over zero-copy performance, flexibility over minimal overhead, and generality over short-term efficiency. Given the era and constraints, those were the right tradeoffs. Today I’d make different choices.
Too much dynamic_cast
PAL made pretty prolific use of polymorphism with runtime type inspection via dynamic_cast. At the time, this wasn’t much of an issue. There was a pattern where in client application bindings where it became a problem; PAL attributes were mapped to the attribute types of the host system. In the simplest approach, the dynamic_cast cost was problematic, but was easily solved by better mapping techniques. So retrospectively, I wouldn’t say PAL’s reliance on traversing the type system was a mistake. However, in todays world, we’d probably solve this in a different way that didn’t depend on the type system at runtime so much.
Relationship semantics were complicated
PAL had the ability to put significant functionality in relationships - that’s the arrows in the graphs.
The DCC UI’s for accessing attributes on relationships wasn’t well supported.
Likewise, typed relationships were sometimes awkward to map to DCC’s. We ended up moving away from
establishing relationships between objects the way we’d initially built it, which was inspired by
ILM’s Zeno, and settled on relationships being expressed as PalRelationalAttr. This was an evolution
that just had to work itself out, as DCC’s evolved.
Exceptions vs. Error Codes vs. ???
PAL used exceptions internally, and we had a strict policy for where exceptions could be used to communicate up the call stack. Under no circumstances were we ever allowed to bring down a DCC. We’d use exception translators to bridge the gaps. But exceptions are a divisive topic, and some codebases disable exceptions entirely, and that’d totally break PAL. I don’t know that there’s a better way, IMHO. Having worked with exceptions on Linux, I quite like them, though on Windows, I don’t. It might have been better to use a cross platform error handling system.
Networking code is hard
When we set out to build PAL’s networking components, we’d initially spec’d out a system built on ASIO that used TCP for a command layer, and UDP for broadcasting data to multiple clients. We did get that system working, but only in dedicated huntgroups, where only our system was running. Once we were on the open farm, collisions and dropped packets wrecked us. We ditched the UDP broadcast idea, and instead adopted a torrent-like system over http, where clients would relay data to other clients. It’s easy to take low level networking reliability for granted.
Render farm constraints
We discovered that sims running in our render farm would stall for long periods of time. We figured out that this was whenever a process on that computer was communicating over the network or writing to disk. Once I found the right systems guy to talk to (I love systems guys) he gave it to me straight: the render farm was engineered to be cheap, not good. Hence, the logic boards in those computers only had a single I/O controller. If a render got scheduled on the same box as our sim, we’d be dead in the water until it was done. That was surprising. Once we knew that, we made our protocols less chatty, and did a lot of buffering of output data, and offloaded all I/O to background threads.
Looking busy can get you in trouble
Our sims were pretty good at pegging CPU’s. Once we started running distributed sims on the render farm, we’d see sims die that we couldn’t explain. It took some deep dives into system logs, and some social engineering to get to the bottom of it. It turns out that whenever the folks that ran the render farm saw high utilization on any particular host, they’d assume the scheduler oversubscribed it, so they’d reboot it. (Sabotage!) We talked them into checking that it wasn’t one of our sim jobs before they pulled the plug.
Outcome
PAL didn’t make simulation solved. It made simulation viable.
By separating evolving research code from production-facing infrastructure, we reduced the integration tax that had previously made simulation risky. Integrating new solvers meant new PAL bindings - not new pipelines. This faciliatated continual iteration on the solvers we had, making them better over time.
Simulation adoption expanded. Disciplines outside of cloth and hair TD’s started using our tools. Like rigid body and flesh simulation for animators, rigid bodies for set dressing, fluids and rigid fracture for effects, and armature rigging for articulators. Artistic reach expanded.
Simulator improvements accumulated instead of resetting. Infrastructure improvements accumulated instead of resetting.
The question shifted from “Can we afford to integrate this?” to “Can this fit into PAL?”
That shift mattered.
PAL repositioned simulation infrastructure from a per-show expense to a studio-level investment. For over a decade, that compounding effect paid off, and Pixar was fundamentally changed by it.
Broader Reflection
PAL wasn’t primarily about physics. It was about trust.
Production trusts systems that don’t crash, can be inspected, restarted, and explained. Research thrives where experimentation is cheap and iteration is fast.
PAL created a boundary where both could coexist.
When technology is evolving quickly, the most valuable thing you can build isn’t another feature. It’s a stable surface that lets innovation compound.